
SIAM UQ
Hi all! Dr. Mandy Muyskens here and I’ve just returned from a perilous journey across the country (to Minneapolis). Not as cool as I made it sound, but I did just return from a trip to a professional conference called SIAM (Society for Industrial and Applied Mathematics) UQ (Uncertainty Quantification). At this conference, there were hundreds of brilliant researchers who all care about what Real Good also cares about: understanding how things work and being specific about when and how much they can go wrong. We were honored to be invited to give a talk in a session entitled “Recent Developments in Statistical Methods for Uncertainty Quantification.” It is very important to interact with the research community at conferences such as these to make sure we are headed in the proper direction and to get ideas from people outside of our immediate community. I’d like to think we also gave them some ideas as well!
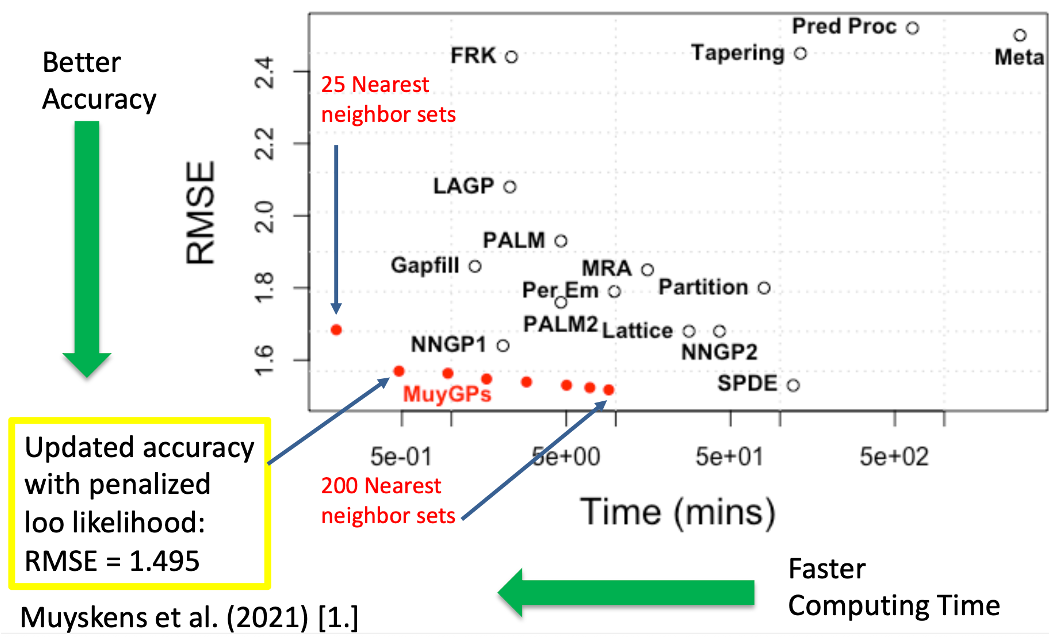
Of course, I took the opportunity to talk about Gaussian Process Models for Big Data in AI. I started off by introducing MuyGPs, which is a methodology for a large number of observations for computationally efficient Gaussian Process Models my team developed at the Lawrence Livermore National Laboratory. Remember, Gaussian Process models have interpretation, uncertainty quantification, and natural data attribution, where we can interpret the percent data that influenced the model. I showed my favorite benchmark result, where MuyGPs has shown to be more accurate or faster than other approximate Gaussian Process models. However, to use AI applications have not just a large number of observations, but also a large number of variables in each observation so we need more complex models than this to work on AI.

Next, I showed results of some of our early wins with replacing Neural Networks in diffusion models and language models. I showed (using super small datasets and a very small amount of computing) that we have some promising initial results. First, this is a picture of generated creative handwriting, where we know exactly why each pixel was generated and from what proportion each training datapoint played in making that image. Next, from only having War and Peace as training (not fine tuning mind you, this is training from scratch) the LLM was able to start learning some words, capitalization, and punctuation rules, but admittedly could be improved.

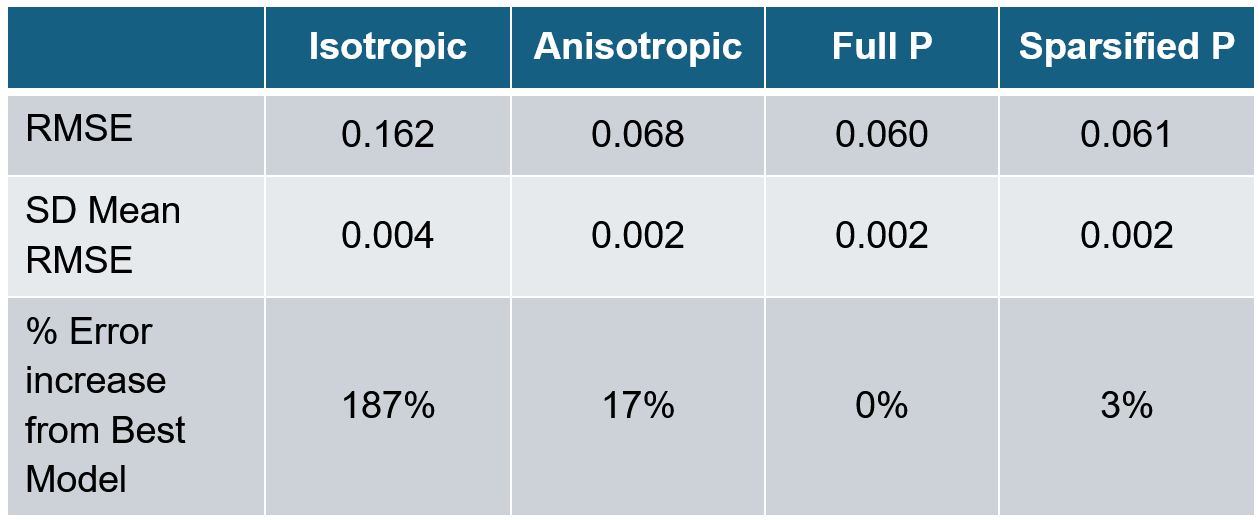
Finally, I discussed the variable selection model that I have been working on. I showed some very early results that we can make an improved model that (Sparsified P below), where we get improvement over the models that everyone first (isotropic, anisotropic) but have WAY fewer parameters than the “Full P” method. Essentially, this means I get more accurate solutions with only a little more computing time and complexity than more basic GP models on this benchmark dataset.
A major focus of the conference was questions about how applied math and specifically the field of uncertainty quantification survives into the future in this new world of AI. As an observer, it was interesting to hear brilliant minds start to think about the problems we have been working on day in and day out here at Real Good. One scientist actually said they thought UQ and AI should stay separate because there is no way we could ever have proper mathematical rigor with the speed of machine learning changes. This is absolutely crazy! Ignoring problems that are and will be impacting everyone in the world through AI is irresponsible, especially when we know those researching machine learning need help developing these important mathematically complex methodologies. Good thing there are those of us who strongly disagree!
One plenary talk I found particularly interesting was Dr. Laura P. Swiler where she discussed the trends of uncertainty quantification over her distinguished career at Sandia National Laboratories. She discussed how hard it is to actually answer the question of how wrong we can be because there are so many ways we can be wrong building models. She imagined that in a perfect world, we would be able to determine where the “wrongness” came from and attribute it to:
numerical errors and approximations in convergence
input parameter uncertainty
model form uncertainty
data uncertainty
surrogate modeling uncertainty
extrapolation uncertainty
analyst-to-analyst uncertainty
You don’t need to understand each of those individual components to understand her point that telling how wrong we may be in modeling is a really complex problem. Further, we will need a host of methods, not just one solution, to think about how much we should trust something that comes out of mathematical models, which includes all these AI tools.
Now, not to be crass, but there also was a plenary talk about “NUTS.” You read that correctly, an academic thought it was a good idea to name their method “NUTS” (No U-Turn Sampler, https://arxiv.org/abs/1111.4246), I guess probably so that they could say they were working really hard on NUTS all day. OK, I had a bit too much fun with this one, but I couldn’t help but laugh at the juxtaposition to the very serious science and NUTS.
The biggest surprise of the conference for me was the positive reaction to the REAL rating. As a shameless plug (I couldn’t resist), I put a short slide introducing the REAL rating so that the audience could learn more and start using it today in their classrooms, research, or otherwise. Now, you may not know this about modern scientific conferences, but you can gauge the excitement of the audience by how many audience members whip out their phones to take a picture of your slides. We had a moment where multiple people took pictures of the REAL rating slide together! Further, there were a lot of follow-up conversations as people thought this could really make a difference in terms of transparency in research. So needless to say, I have come home with new excitement and urgency to make it as easy as possible for new adopters of the system and to share it with everyone!

